- はじめに -
文章がローランド(@roland_0fficial)様っぽいか判定するサービスをつくった。
できてた
— ばんくし🎃 (@vaaaaanquish) 2020年12月26日
『ばんくし』は俺以外でした https://t.co/MxSTPmKVWL #oreka_oreigaika via @vaaaaanquish
学習済みモデルをダウンロードし、WebAssemblyで形態素解析、機械学習モデルによる判定を全てブラウザ上で処理する。
この記事は、そこに至るまでメモ。
- 技術的な概要 -
何が面白いのか簡易図
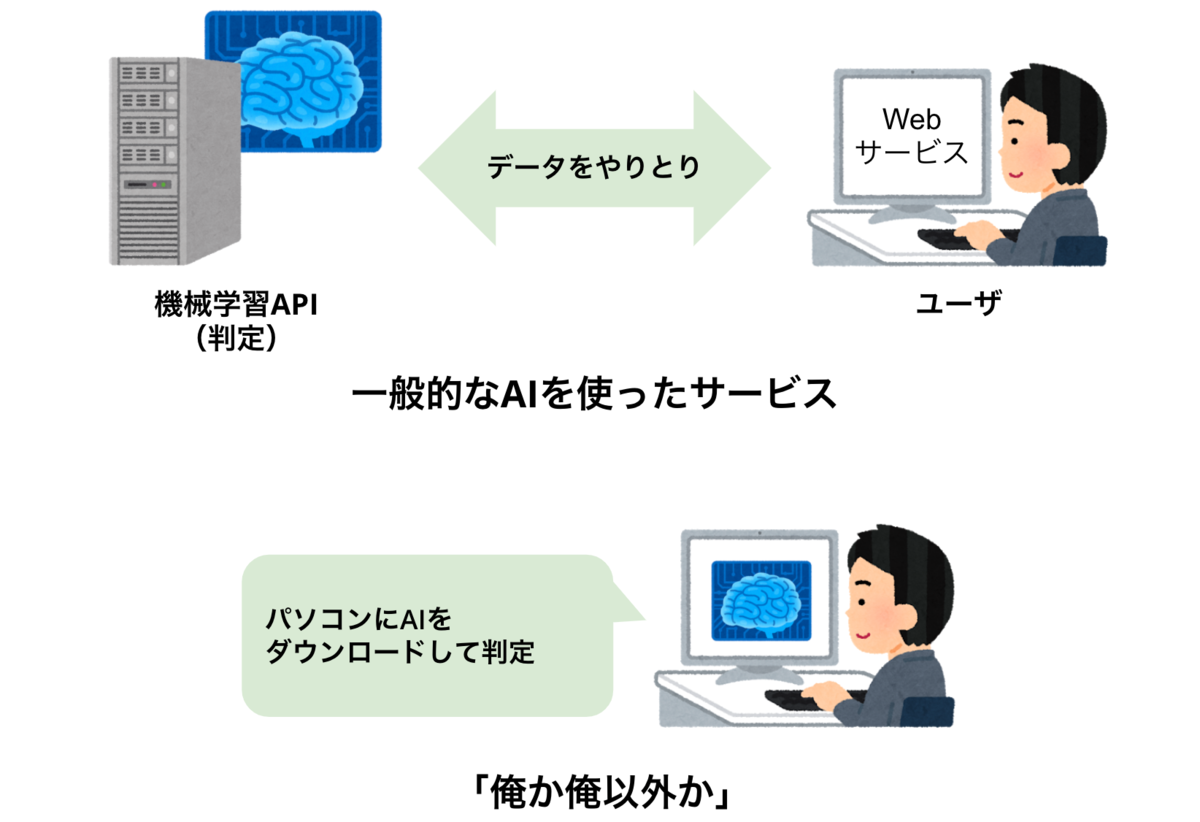
学習済みの機械学習モデルをダウンロードして、手元のブラウザ上で動くjavascriptだけで、テキストの処理や判定をするというもの。WebAssembly(以下wasm)自体はまだ出始めの技術ではあるものの、面白い試みが近年増えて来ているので興味もあって作った。
- データの収集 -
我らがローランド様のTwitter、Instagramのテキスト部分をクロールした。
twitter.com
https://www.instagram.com/roland_0fficial
思ったよりツイートしていなかったので、ローランド名言bot、名言集のようなものを探したり、著書から文章を集めて、4106件のローランド様の語録データを作成した。
ローランド様以外のデータは、偶然ダジャレを判定する - Stimulatorで収集した1916747件のツイートデータが手元にあったので、そちらからサンプリングして不正解のデータとした。
- 技術的な構成 -
使ったものを端的に挙げていく。
形態素解析や機械学習モデルに関しては、以下の記事に書いたものを利用した。
以下repo内にrust製の形態素解析器であるlinderaをwasm-packでwasmに変換し、webpack、Next.jsを経由して動かすExampleを公開しているのですぐ再現できるはず。
自然言語のベクトル化は、上の記事内でもサーベイした通りPyTorchなどを使う幾つかの方法があるが、再現実装が伴ったものが少なかったので、大人しくFastTextを利用した。判定のコアとなる機械学習モデルの部分はXGBoostやLightGBMなど概ねのモデルがC++で書かれているので、Emscriptenでwasmに変換して利用した。これらの詳細は後述する。
フロントはNext.js、ホスティングにGAE、モデルファイルの配信にGCSを利用した。以下のような構成になった。
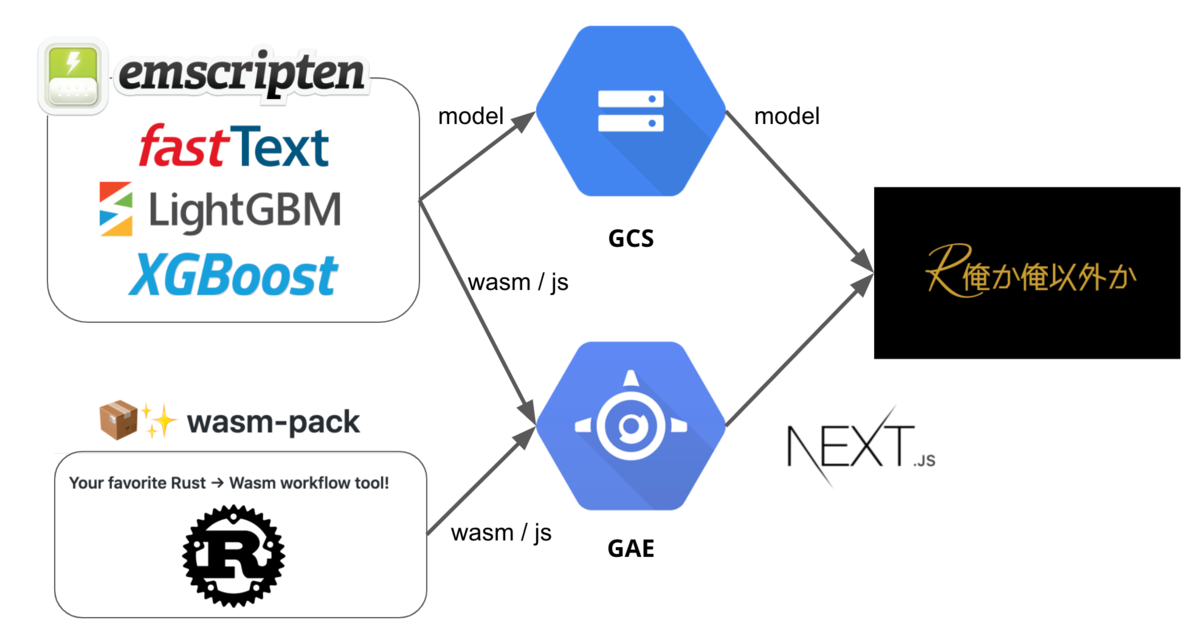
最初S3だけで機械学習Webサービスホスティングと銘打って楽しんだりFierbaseを使って遊んでいたが、不便さと通信量に対する料金が怖くなってこの構成になった。
- モデル周りの話 -
FastTextが0.9.2からWebAssenblyのbindingを配信している。
元よりFASTTEXT.ZIPの論文*1などモデルの圧縮を頑張ってたのは知っていたのもあって、ちょうど良く試そうとなった。
FastText含むモデルのC++コードをwasmにするにあたっては、Emscriptenを使う。
普通にgcc、g++やclangのバージョン、リンクなどハマり所があるので、素直に公式のDockerを使うと良い(ハマった)。
$ docker pull emscripten/emsdk $ docker run -it emscripten/emsdk bash $ em++ --version emcc (Emscripten gcc/clang-like replacement) 2.0.11 (6e28e4fa4fa1bc50d58b9ddbbb9603a3cf21ea9e) Copyright (C) 2014 the Emscripten authors (see AUTHORS.txt) This is free and open source software under the MIT license. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
基本的にはC++のMakefileをそのまま追記してgccをemmに変更し、利用したい関数をEXPORTED_FUNCTIONSに入れてbuildすれば動く。最も参考になるFastTextのEmscriptenのbuild用のMakefileがかなり参考になる。一方masterのMakefileじゃ動かない*2ので、Emscriptenのバージョンを下げてbuildする必要もある。
実際にwasmができても単純にwasm-loaderとwebpackを介するとロードできなかった。
これは、Emscriptenがwasmとのグルーコードとして吐き出すjsがかなりヤンチャな事と関係している。hoge_wasm.js内のimport.meta.urlをdirnameに書き換えた*3上でhoge_wasm.wasmへのpathを書き換え、hoge_wasm.wasmをNext.jsの静的配信に切り替えた。その上でグルーコードをまるっと書き換えてDynamic Importで読み込めるように書き換えた(別途公開します)。
LightGBMのバイナリもPython bindingで学習したものをwasmから読み込もうとした際に、全ての結果が0になる謎の現象に当たったので、一旦C++でtrainスクリプトを動かしてloadすると上手くいった。学習中にLGBMのコード読んだがこれはイマイチ原因がわからなかった(LGBMのissueに唯一あるwasm関連のissueも「wasm対応出来てるか知らんけどcloseで」となっているので誰も分からない説がある*4)。
最初、全てのモデルファイルを合計して雑なフロントから読み出してみると、1266MBをロードしていた。犯罪級だ。
FastTextに量子化の機能が付いているのは事前にF&Qで見ていたので、それを試した。
FAQ · fastText
How can I reduce the size of my fastText models?
fastText uses a hashtable for either word or character ngrams. The size of the hashtable directly impacts the size of a model. To reduce the size of the model, it is possible to reduce the size of this table with the option '-hash'. For example a good value is 20000. Another option that greatly impacts the size of a model is the size of the vectors (-dim). This dimension can be reduced to save space but this can significantly impact performance. If that still produce a model that is too big, one can further reduce the size of a trained model with the quantization option.
元の論文と照らし合わせながら、パラメータを変更して何度かtestしてみて、精度が落ちなさそうな所で以下に落ち着いた。
./fasttext supervised -input ../train_ft.csv -output ft_min -bucket 40000 -epoch 25 -wordNgrams 2 -cutoff 10000 -retrain -qnorm -qout
gbdtもpruningやcompressingみたいな単語でググれば何か先行事例あるだろと思って探して、ちらほらあるものの、目ぼしい物を見つけられなかった。「Lossless (and Lossy) Compression of Random Forests*5」みたく、最小の表現モデルを探したり寄与の低い枝を切ったり面白い分野だと思うが、まあでも今はDNNとかの方が圧縮できるしあまりという感じなのだろうか…
これらは一旦愚直に「木の深さ」「木の数」を制限していき、モデルサイズをやりくりする方法を取った*6。
最終的に全体で241MB までダイエットした。あと1桁落としたかったが、精度が犠牲になるならまあ同意を取ろうという事で今回は妥協した。
同意を取る画面で私がローランド様のツイート全部見た上で厳選したツイートが見れるのでそれで我慢してもらう。
- おわりに -
12月頭にWebAssenbly nightというイベントがあって面白かったので、なんかコツコツ勉強していたら出来ていた。ありがとうWebAssenbly night。
Webサービスのアイデアは20秒くらい、フロントエンドも最近慣れてきて1日かからずできたが、wasm buildして配信するまで結局1週間くらい唸った。まともな情報もないし、育児くらいしんどかった。
信頼できるのは以下だけで、後の情報は絶対古いか動かないかが入ってくるので無視した方が良いと思う・
とりあえずこのチュートリアルをなぞるだけにして頼むから。
この記事の内容も最悪誤情報になるなと思った所は削った。
次はPyTorch WebAssenblyを試すのと、最近やっているフロントエンド周りの勉強のまとめを書ければと思う。

*1:JOULIN, Armand, et al. Fasttext. zip: Compressing text classification models. arXiv preprint arXiv:1612.03651, 2016. https://arxiv.org/abs/1612.03651
*2:https://github.com/facebookresearch/fastText/issues/1166
*3:https://stackoverflow.com/questions/60936495/module-parse-failed-unexpected-token-937-with-babel-loader
*4:https://github.com/microsoft/LightGBM/issues/641
*5:PAINSKY, Amichai; ROSSET, Saharon. Lossless (and lossy) compression of random forests. arXiv preprint arXiv:1810.11197, 2018. https://arxiv.org/abs/1810.11197
*6:How to Tune the Number and Size of Decision Trees with XGBoost in Python https://machinelearningmastery.com/tune-number-size-decision-trees-xgboost-python/