- Python のパッケージ管理ツール概論 -
まずはじめに、2020年3月現在、主に「Python パッケージ管理」等のワードでググる と出てくる3つの大きなツール、pip、pipenv、poetryについて概論的に説明する。
最も表面的な概要だけ把握するために、私が社内向けに作成した資料を以下に引用する。
社内LT向けに作成した資料より加筆の上抜粋 多くは後述するが、ここでスライドが主張している重要な点を文字におこしておくと以下のようになる。
pipenvはPyPAが開発しているツールで同じくPyPAが開発するpipの機能を補っている pipenvとpoetryの大きな"機能"の違いはパッケージのbuild・publishをサポートしているかどうか pipenv、poetry以外に他にも多くのパッケージ管理ツールが存在する 本記事のタイトルを解消する上で重要な点は上2つであり、これらについてpip、pipenv、poetryの概要を示しながら本章で触れていく。本記事においては、Anacondaや他ツールについては本筋ではないため、本章の最後に簡単にまとめて触れる。
pip
pipは、最も基本的なPython のパッケージ管理ツール、より正確にはパッケージインストーラ である。PyPI *1 より、Python モジュールをインストールするためのツールであり、Python の拡充提案、プロセス、設計、標準を決める文書群であるPEP内の、PEP 453 によって、Python が公式にサポートするツールとなっている。Python3.4からは、Python に内包されデフォルトでインストールされる。github.com
パッケージ管理の側面から見た場合は、以下のようなrequirements.txtというファイルを記述し、そのファイルで利用するモジュールのバージョンを管理する形式を取る。
numpy<=1.0.0
pandas==1.1.5
jupyterlab>=2.0.0
...
pipは具体的に依存treeを生成するような依存解決は行わず、順番にインストールしていき、サブモジュールの依存関係に問題があった場合は上書きする事で解決する。上記であればpandasやjupyter labによってnumpyはバージョンアップしたものが入る事になる。
pipと後述するpipenvの関係において、上記を背景とし一般的なプログラミング言語 がプロダクト開発でそれを必要とするのと同様に「依存関係を解決する」「lockファイルを生成しサブモジュールを含む全てのモジュールバージョンをhashで管理する」事が求められた結果pipenvが開発された 、という認識は間違いではない。実際、上記のrequirements.txtだけではパッケージングを行う事は出来ない事は想像できるだろう。wheel 、setuptools といったツールでパッケージング、また別途PyPAが作成するtwin を用いてパッケージレジストリ であるPyPI にアップロードするというライフサイクルに倣っており、バージョン固定や開発環境管理は各ユーザに委ねられていた。pipenvやそれら以外のツールについて具体的には後述するが、pip自体が手続き的なバージョン管理方法やパッケージングの方法を持っていないが故に、別ツールとしてパッケージングツールが作られていった結果として、今多くのパッケージング管理関連ツールが生まれ続けるPython の環境になっているとも言える*2 。
pyproject.toml (PEP 518)
1つ目に、PEP 518 で制定されたpyptoject.tomlというフォーマットがある。後述のpoetryで利用されている事は広く知られているが、pipもまたpyproject.toml対応しているという点が重要になる。
pyptoject.tomlは、以下のような単一のtomlファイルをrequirements.txtやそれらを参照するsetup.pyの代替とする事が出来るようになっている*3 。
[ install_requires]
pandas = "*"
[ build-system]
requires = [ "setuptools" , "wheel" , "toml" ]
これはpip単体では大きな旨味はないが、pyproject.tomlが単一のファイルでパッケージのメタデータ や依存ライブラリ、フォーマッタやenv環境、buildの設定を記述できる 事を踏まえ、後述のpoetryのようなPEP 518対応のパッケージングツールと組み合わせる事で、ファイル及びツールを小さく集約する事が可能になっている *4 。
かなり簡単に言えば、これだけ書いとけば開発関連の設定はオールオッケーなsettings.tomlである。
pyproject.tomlについてより詳しくは後述するが、現在最も注目される仕様の1つであり、把握しておくと良い。
pipenv
pipenvは、pipに対して、依存解決およびlockファイル生成、env環境制御機能の提供を行う、PyPAが開発するパッケージ管理ツール である。依存解決およびlockファイル生成にはpip-tools、env管理はvirtualenvを利用しており、それらを1つのPipfileと呼ばれる独自フォーマットで管理できるツールとなっている。github.com
Pipfileは以下のようなフォーマットになっている。
[ dev-packages]
coverage = "*"
yapf = "*"
mypy = "==0.580"
[ packages]
numpy = "<=1.0.0"
pandas = "==1.1.5"
[ requires]
python_version = "3.9"
ここでは、開発用のパッケージ、モジュールが利用するパッケージ、envの設定を記述する事ができる。
pipとの大きな違いは、先に挙げた依存解決、lockファイル生成、env環境の制御である。
依存解決アルゴリズム では、pip-tools内で先程の2020-resolverと同様のbacktrackingを利用している*16 。github.com
env環境については、同じくPyPAが開発するvirtualenvの機能をwrapし、env環境を提供する形となっている。github.com
wheel やtwin )を利用してbuild, publishを行いPyPI に公開するライフサイクルとなっている。publishに関連したそれぞれのツールもまたPyPAが開発しており、このような目的毎に分割されたツールを組み合わせたりwarp したりしてパッケージングすることが、PyPAが示すPython パッケージングのライフサイクルの主たる形であると言える *17 。
poetry
poetryは、pipenvに対して先のpyproject.tomlの仕様を拡張を利用し、依存解決からlockファイル生成、env環境管理、パッケージングまでを行えるようにしたパッケージ管理ツール である。先のPipenvと違い、PyPAではなく、1ユーザである@sdispater が主導し開発 されている。github.com
READMEには『Why?』という章があり そこでは、pipenvに対する課題とpoetryを作成した経緯が書かれている。要約すると以下の3点になる。
setup.pyやrequirements.txt、Pipfileを導入せずcargoやcomposerのようにbuildしpublishしたい
pipenvの意思決定のいくつかが好みでなかった
より良い依存解決リゾル バの導入
[ tool.poetry.dependencies]
python = "^3.6.2"
pandas = "*"
[ tool.poetry.dev-dependencies]
coverage = "*"
yapf = "*"
mypy = "==0.580"
[ tool.poetry]
name = "sample"
description = "This is sample"
authors = [ "author" ]
version = "1.0.0"
readme = "README.md"
homepage = "https://github.com/author/sample"
repository = "https://github.com/author/sample"
documentation = ""
keywords = [ "Example" ]
[ build-system]
requires = [ "poetry" ]
build-backend = "poetry.masonry.api"
[tool.poetry] となっている箇所は、poetry独自の拡張セクションである。pyproject.tomlとしてフォーマットが決まっている事で、拡張セクションを追加出来るようになっており、そちらを上手く利用した形になる。
依存解決を高速に行える だけでなく、backtrackingが依存ツリーを戻る量で制限しているような枝を探索する事ができる ようになっている。具体的には、READMEに書いてある以下のような例でpipenvが失敗する依存解決を遂行できるようになっている。
pipenv install oslo.utils==1.4.0
実際はpipenvが利用するpip-toolsのリゾル バとの比較になるが、このリゾル バの違いによる問題については、pipenvとpoetryの違いに関する章で後述する。
Anacondaなど他ツール
少し記事タイトルと逸れるが、現状を知る意味で概論として他のツールにも触れておく。
Python のパッケージ管理エコシステムは、常々PyPAという団体によって整備され、PEPを通して制定され、PyPAが、インストーラ となるpipを代表にパッケージングであるsetuptoolsやwheel、PyPI へのアップロードはtwine、仮想環境はvirtualenv、依存固定はpipenvとそれぞれ作ってきた経緯がある。
そんな中で、PyPA以外の全く別のツールや似通ったシステムが栄枯盛衰を繰り返しているのは、常々人が作るソフトウェアの難しさに触れる事に近しい。最初から誰もが満足するツールなど作れないし、Python 自体のユーザが増えた事によるOSS 界隈の情勢の変化、影響範囲の拡大、速度、文化など様々な要素がひしめき合った結果、poetryやその他多くのツールが生まれたと言える。
中でもAnacondaは、pipがまだ多くのライブラリのインストールに失敗しバージョンやenvを管理する方法が定まって無かった中で、挑戦的な方法を取ることで出てきたパッケージング管理ツールである。
Anacondaは、Anaconda,Inc という企業が開発、運用している点やその他GUI やenv提供の機能を持つ特徴こそあるが、パッケージ管理の側面でも他ツールとは少し違う独特なツールである。www.anaconda.com
Anacondaは、Anacondaリポジトリ *18 なるpypi のミラーサーバから、「環境に応じた最も良いもの」をインストールする機能を持ったパッケージ管理ツールである*19 。最も象徴的な例として、Python に近い界隈では「numpyが利用するBLAS の違い」についての話題が毎年2,3度バズっている。Anacondaがインストールしたnumpyが早いというものだ。Google 検索「numpy anaconda 早い」と検索し上から記事を見ていけば概ね把握できるだろう。www.google.co.jp Deep Learning 関連ライブラリのバージョンを照合する機能など、手元の環境とライブラリの依存関係を照合する知識がなくとも構築出来るのが1つの"売り"であると言える。
反面、過去何度も多くの開発者やツールが「環境に応じた最も良い物を提供する」事に挑戦した結果と同様に、依存関係の差異に苦しんだり環境を破壊する結果になることもある。特にpipと併用する事がHardlinkによって困難な点が最も大きい*20 。技術的なメリット・デメリットについては以下の記事には目を通しておくと良い。www.anaconda.com
大きな企業単位であれば十二分な基盤やVM を上手く組み合わせAnacondaを利用した理想の環境で開発できる企業もあるだろうが、その破壊的な機能や近年企業規模に応じて有償化する ようになり、導入におけるデメリットも存在するし、もちろん逆に良いこともある。
Anacondaは、過去pipのインストールがまだ不安定だった時期に登場し、依存解決や独自のpackage registryの提供で大きく貢献した。また依存解決リゾル バの改修にも積極的かつ、ミニマムなAnacondaにあたるminiconda も存在しており、大きな一つの勢力であると言える。
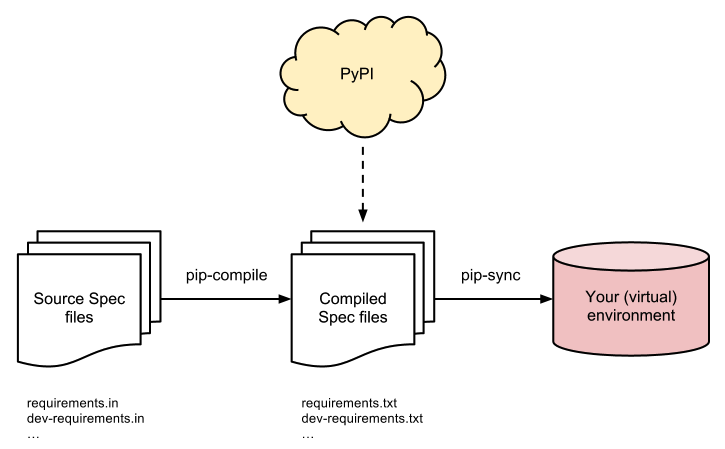
pip-tools を利用する方法、rustで書かれたpyptoject.tomlで管理可能なpyflow等が現状の選択肢に入る。海外ではflit も人気があるようだ。
pip-tools公式repoより ユーザはrequirements.inというrequirements.txtと同様のformatで、自身が利用したいモジュールのバージョンを記載する。pip-toolsが提供するpip-compileコマンドは、inファイルから依存する全てのモジュールのバージョンが固定された状態で記載されたrequirements.txtを生成するジェネレータ の役割を果たす。また、hashを利用した固定にも対応している。ここで生成されたrequirements.txtファイルを利用してpip-syncコマンドでenv環境に流すという構想である。この思想に則りさえすれば、env環境と切り離せるため、複数人での開発等を考えた時、個々に手慣れたenv系のツールを使ってもらえば済むというメリットがある。
pyflowは、rustで書かれたPython パッケージ管理ツールである。github.com PEP 582 にあたるカレントディレクト リに__pypackages__というディレクト リを作り仮想環境のように扱う方針 に対応している*21 。PEP 582はpythonloc やflit 、pdm といったパッケージ管理ツールで採用されている新しい方針である。これによってユーザは、ほぼenvについて意識する事無く複数のPython や開発環境を切り替える事ができるようになる。このようなPEP 582の採用も目新しいpyflowであるが、私自身はパッケージ管理ツールがPython で書かれている理由はほぼないと考えており、依存解決やインストーラ 含めて、より高速な言語で書かれて欲しいという気持ちもあり一目置いている。新興のツールという事もあり、現状では未対応のissueを見てpoetryと比較し利用していないが、挑戦的な選択肢として強く推せるツールとなる。
hatch や、オープンソース のソフトウェア構築ツールであるSCons に則り作成されているenscons 、RedHat が作成したpipenvとpoetryのいいとこ取りをしたminipipenv 等も存在し、小さく機能を収める方向にいくか、理想の依存解決、複合ツールとして大きくなっていくか、どの仕様を採用するのか、違いが見え隠れする状態である。何度も言うが、これらの選択は、その場その場の要件次第でもあると思うので、利用用途の多くなったPython という言語にとって、これらのツールが多く出てくる事自体は喜ばしい事である*22 。
まとめ
ここで一度話をまとめる。冒頭で示した主張には以下のような詳細に分かれる。
pipenvはPyPAが開発しているツールで同じくPyPAが開発するpipの機能を補っている
pipenvは依存解決器の機能を持つが、pipにもその機能が搭載されつつある
pipenvはvertualenvやwheel、twine含めてPyPAが作るエコシステムの一部である
pipenvはresolverとしてpip-tools内のbacktrackingを利用している
pipenvとpoetryの大きな"機能"の違いはパッケージのbuild・publishをサポートしているかどうか
poetryは基本的な機能はpipenvと同じ
poetry独自の機能はpyprojcet.tomlの拡張セクションによるもの
pyproject.tomlには各種設定を詰め込む事ができる
poetryはresolverとしてはpipenvと違いPubGrubを利用している
pipenv、poetry以外に他にも多くのパッケージ管理ツールが存在する
pip-tools、Anaconda 、flit辺りが人気
envやパッケージングなどの機能をどこまでをサポートするかの違い
package registryの違い、pyprojcet.toml(PEP 518)やPEP 582の採用の違い、リゾル バの違い
ゾル バを採用するのに各ツールの違いがある。
- pipenvとpoetryの技術的・歴史的背景 -
本章では、ネット上に多くあるpipenvとpoetryに関する議論で出てきがちな疑問、不満を以下の通りに分類し、それらに対してそれぞれ背景を追う形で紐解く。
パッケージングについて
lock生成までの速度
pipenvは開発がここ2年滞っていた件
pipenvのissue対応
PyPAの開発フロー
活動や対応に関するゴシップ
上記を追う中で、poetryがどのような技術を採用し、pipenvが何故そうしないのか、逆にpipenvのどこが良いのかを詳しく見る。
パッケージングについて
poetryはpipenvと違い、pyproject.tomlを利用する事で、指定のbuild systemないし、独自のセクションを利用して、pyproject.tomlのみでパッケージング出来るという話がある。pipenvとpoetryの機能の違いで最もよく挙げられる点である。
自系列を追うと、PEP 517 が2017年9月、pipenv 1stリリース は2017年1月であり、前後関係としてPyPAがPipfileについて検討している間はpyproject.tomlのPEPのacceptに至っていない 事がわかる。
また、pyproject.tomlを使えば全てのパターンのbuildが行えるかと言われると、元々setup.pyを書いていた事を考えれば当然そんな事はない 。setup.pyでC言語 で書いたサブモジュールをbuildしたり、外部のライブラリとリンクする実装などが代表的である。PyPAとしては、そういった問題の解決のためにwheel やsetuptools も作っている訳なので、役割を考えればsetup.pyやrequirements.txtが担っていた役割とpipenvが持つ依存解決、バージョン固定、env管理という問題は別であるという認識になるのは自然である。
実際、poetryはそういったユースケース に対してbuildを提供する方法として、build = "build.py" のような機能を一応持っている。ただ以下issueの通り、ドキュメントには未だ記載はなく機能として安定、サポートされている状態ではない。github.com Python という言語において非常に重要であるし、tomlだけで管理できるものはないだろう。またbuild scriptの実行もPyPAが長年かけてPEPで制定、整備、開発してきた部分であるので、それらへの対応を新しい開発者やツールが対応するのは相当な熱量がないと難しい部分もある。
pyproject.tomlに集約されたり、パッケージングまで行える事で差別化が図られる一方で、こういった多くのbuildにどこまで対応するかがツールによって変わってくるよという話になる*23 。
lock生成までの速度
「pipenv lockが遅い」「poetry lockが早い」というのは、よく挙げられる話題の1つである。
lockファイル生成速度に関してpipenvのissueが乱立していたり、Slack、Discode 、SNS 各所で議論されている。#356 、#1785 、#1886 、#1896 、#1914 、#2284 、#2873 、#3827 、#4260 、#4430 、#4457 、…
まず、先にpipenvとpoetryの依存解決リゾル バのアルゴリズム の違いがある事を挙げた。そうすると「pipenvもpoetryの実装を真似すれば?」「pipenvもpoetryのようにPubGrubをベースとした依存解決を行えば良いのではないか?」という意見を思い付くのは自然だろう。
この意見を述べる前には、PubGrubアルゴリズム の特性と、その裏側で利用するhash値の生成方法の違いを知る必要がある。
ruby のrubygems も同様の方法を取っている。Python におけるpackage registryはPyPI になるが、PyPI のAPI がjson -api へ移行したことその内容にセキュリティ上の懸念がある事 が、pipenvとpoetryの依存解決方法のアルゴリズム 、そして実装の違いに影響している。
まず前提として、PyPI は2017年12月にそれまでのHTMLを利用したAPI エンドポイントをLegacy API とし、json -api の提供を開始した。これは、他のpackage registry同様の内容で、特定パッケージのhash値を含めて返してくれるというものである。warehouse.pypa.io json -api 提供開始時期の問題もあって、poetryははじめからこのjson -api が返す結果の多くを信頼し、依存解決を行っている。一方pipenvはこのAPI の結果を使わず自前でhash値を計算している。ここがpipenvとpoetryの根本的なlockファイル生成速度の差に繋がっていると言える。
さて、このjson -api はpipenv開発開始以降に提供開始されたものではあるものの、pipenvに対しても「このjson -api の結果を信頼し依存解決を行い、バージョンをlockするように変更すれば良い」という意見に繋がる。これにもいくつかの問題がある。
json -api の1つ目の問題として、このjson -api がPEPによって標準化されていないjson -api のドキュメントからLegacy APIのページ に行くと以下のような文言がある
The Simple API implements the HTML-based package index API as specified in PEP 503.
Legacy API についてはPEP 503 、その内容については、メタデータ のバージョン2.0にあたるPEP 426 に書かれており、メタデータ のjson 互換オブジェクトを定義した2.1にあたるPEP 566 もあるが、json -api について記載されたPEPは現状存在しない。PyPAとしてpipenvにこのAPI の結果を利用できない1つ目の理由になる。一方この問題は既にdiscuss.python .orgで起案されているので、こちらをウォッチすると良いだろう。discuss.python.org
json -api の2つ目の問題として、PyPI (正確にはhttps://pypi.org/) のartifact hashの一部が一度インストールしてみないと分からないという点がある。PyPI は、一度アップロードしたバージョンを同じバージョンで上書きする事はもちろんできない。一方、build済みのパッケージをtar.gzにdumpしたwheel形式以外に、buildスクリプト 含めたsdist形式をアップロードできる。後者は、そこに正しくメタデータ が設定されていない限り、特定バージョンのartifact hash自体は一度インストールしてsetup.pyを動かすまで未知になる。この未知のhashが厄介者になる。
PyPI は、一時的なhashを返してはくれるので、全幅の信頼を置いて依存解決の情報として使う事もできるし、全く信頼せず依存解決に必要な各バージョンのbuildスクリプト をダウンロードして手元でbuildしてhash値を計算するという事もできる。poetryは一部をjson -api とし一部を手元でbuildする方針を取っており、pipenvは先述のPEP問題を含めて後者のように完全に手元で全てのパッケージをbuildする方針になっていた 。これだけでも、pipenvが遅い理由が容易に想像付くはずだ。
この違いはあるものの、pipenvは、buildしたパッケージを出来る限りキャッシュして高速化する改修を過去何度も行っているだけでなく、2020年5月のReleaseではJSON -API ではなくURLフラグメントからhashを計算する形で依存解決の高速化を行っている。github.com #2618 、#1816 、#1785 #2075 辺りの議論を追うと良い。
そしてもちろん、poetryも一部のパッケージを手元でbuildしている訳なので、そのパッケージを挙げて「lockが遅い」と指摘するissueが存在するし、poetryのドキュメントにも記載がある。github.com python-poetry.org 実装の問題というより、思想としてartifact hashをどう考えるか、どう処理するのかの違いにlockファイル生成の速度の差がある と言える。
そして先に出てきた、依存解決リゾル バのアルゴリズム の違いも、この問題に起因している。手元で多くのパッケージをbuildする方針の場合、PubGrubが、依存解決を行いながら、その場に応じてパッケージをbuildする機能を持つ必要がある。PubGrubは、そのアルゴリズム の特性上、途中でbuild処理をしながらその結果を比較するロジックを実装する事に向いていない。これについては、先程のpipの2020-resolverの議論でもpoetryの作者が指摘しており、poetryの作者がMixologyとして依存解決リゾルバのロジックをpoetryから切り出したにも関わらず、2020-resolverのロジックとして採用されなかった という背景にもつながっている。ここで、適切にbuildしながら依存解決を行うPython によるPubGrub実装があれば話が進む可能性はもちろんあり、pipgrip 等のOSS 実装が出始めてはいるといった状況である。
PyPI メンテナが書いた以下のブログに理由を含めて記載されている。dustingram.com
PyPI のミラーが作られる」だとか「setup.pyを捨て全てがpyproject.tomlになる良い方法が提案される」だとか「PyPI サーバ内でbuildが走る」だとか複数の道があるわけだが、歴史の長いPython パッケージングの問題やbuildスクリプト が走る事でのセキュリティの懸念、サーバの金銭面などを全て解決されるには時間がかかるのは当然と言える。
pipenvは開発がここ2年滞っていた件
pipenvには「開発が滞っている」「2年更新のない死んだプロジェクト」などの指摘が多くある。実際、2018年11月(v2018.11.26)から2020年5月までReleaseがなかった。2020年5月のReleaseも、当初予定していた2020年3月から4月21日に延期され、4月29日に延期、その後5月にReleaseされたという背景があり、この辺りを挙げ開発が滞っているとする指摘も多い。
これらは、2020年のRelease Noteやtracking issueを見るのが良い。discuss.python.org https://github.com/pypa/pipenv/issues/3369
ここまで示した通り、pipenvはPyPAが開発する多くの他プロジェクト、pipやvirtualenv、setuptoolsに強く依存しているし、その意思決定の多くがPEPという大きなプロセスを通して行われている。空白の2年間の如くpipenvが止まっていたように見えるだけで、関連度が高く、依存した多くのプロジェクトの改修を行っていた訳で、開発が滞っているという指摘自体が間違っていると言える。
なによりPyPAはNumFOCUS といった支援団体があるとはいえ全員ボランティアであるし、Release Noteを書いているDan Ryanは仕事をしながら20%ルールの範囲で開発を行っていると書いてあるしで、外から多くを求めるだけというのは間違いだろう。またこのRelease Noteには「Other changes in the project」という章がある。それはProcess changes、Communications changes、Release cadence & financial supportの3つに分かれており、PyPI への貢献のプロセス、コミュニケーションを変える事を約束し、別の形で「パッケージングエコシステムに対して」貢献できる形を提供すると発表している。
議論やcommitmentに至る程の背景知識がないが、このパッケージング問題に金銭面で貢献したいといった場合は、以下を読みdonate.pypi.org に行くと良いだろう。pyfound.blogspot.com
pipenvのissue対応
poetryが個人開発から始まっているのに対して、pipenvがPyPA主導である事から、issueへの対応の違いが指摘される事がある。「pipenvはissue対応が遅い」といった意見だ。これは、PyPAが元々issueを多く使っていない事に起因しているが、pipenvでたまに返信があるissueもあったり、ツールも分散しているので一見ではissue利用の思想について把握しづらいとも言える。
さて、先にpipの2020-resolverの問題の相談先として以下を挙げた。
これに加えてパッケージングに関しては、以下のような場所の議論を追う必要がある。
メーリングリスト 、freenodeをチェックする事が求められる。packaging.python.org
一見混乱するかもしれないが、開発者からし てみれば、接触 確認アプリCOCOA がissueを利用していないにも関わらず未対応であった事を指摘していた人と何ら変わらないので、正しく議論したい場合は念入りに読み込んで、適切な場所に意見を投稿すべき、という話になる。
PyPAの開発フロー
PyPAの開発フローしんどい問題も少しだけある。もちろん影響範囲が大きいし、PEPや歴史的背景を持つ大きなプロダクトなので当然ではある。
例えば、実際「pipenvに一度貢献したがもうやりたくない」といった意見もある。github.com python devのSlackでパッケージング管理問題に触れた時、多くの回答とフローを用意され尻込みしてしまった経験を持っている。
qiita.com
pipenvのrepogitoryの以下ディレクト リを見ると、vendoringされたツールが多くあるのが分かる。https://github.com/pypa/pipenv/tree/master/pipenv/vendor PyPI から消えて動かなくなったら困る」といった再現性が必要な場面で有用な手法である。
一方で、ことPython においてはvendoringに関連した文化やツールがそもそもないので、pipenvにその問題を指摘するissueが立ったり、vendor先のツールに「このrepoメンテする意味ある?」といったissueが立ったりしている。github.com github.com Python という言語内でのvendoringの文化として浸透していない証拠とも言える。
ただ、開発フローに関しては、個々時々に応じて対処していけば良い問題であって本質的ではない。貢献する気概を持って貢献するだけだろう。そして何より、先述の2020年5月のRelease Noteを使って体制を改善するとまで言っていることからも、PyPAが真摯にこの課題に向き合っているのが分かるので、期待する所でもある。
まとめ
本章のpipenvとpoetryの違いについて、以下にまとめる。
build/publishの機能の違いはpyproject.toml誕生の前後関係とPyPAのエコシステムの思想からくるもの
lockファイル生成速度は、PyPI のjson -api の結果をどこまで信頼し、どこまでパッケージを自分でbuildするかに関係
依存解決リゾル バの違いもここに縛られている側面がある
解決するにはいくつかの方法こそあるが、下位互換やセキュリティ、金銭的な側面の課題もある
Pipenvはissueではなくメーリングリスト を利用して開発が進んでいる
徐々にissueでの議論も進んでおり開発フローの改善も進む
poetryの方が開発体制が良いという訳では必ずしもない
それぞれゴシップ的な炎上を経験しておりディスカッションに参加する場合は丁寧な理解をしておくと良い
念の為フェアに補足しておくと、pipenvには、PyPI にアップロードされたパッケージが変更されていないか等の脆弱性 を確認するPEP 508 に則ったpipenv checkの機能もある*25 。ある意味特徴的な機能の1つだ。pipenv.pypa.io
- poetry大臣としての活動記録 -
ここまで、Python のパッケージング管理ツールについて取り扱ってきた。そして、私が所属する企業、チームでも、実際にpipenvによるパッケージ管理とデプロイ、CI/CDが使われていた。しかし、運用する中で前述のようなパッケージング管理ツールの違いを踏まえて、社内の課題と見比べ、poetryへの移行を行う形となった。本章は、その移行作業の目的や判断基準、感想を綴るものである。
重要な分岐点になった、以下の3つのセクションについて書いていく。
VPN 必須なpipenv lockがかなり遅かった乱立するファイルと管理場所
gokartなどOSS との管理方法統一
VPN 必須なpipenv lockがかなり遅かった私が所属する企業では、社内のPyPI を通してpipによるインストールを行っている。そして、社内PyPI への接続にはVPN が必須であった。
ちょうどコロナで全社でのリモート化が進み、在宅勤務が増えた事でVPN の負荷が増大、それに伴ってpipenv lockに膨大な時間がかかるようになっていた。基本的に1時間以上は基本、大きなrepoでは2,3時間を要して、途中で接続がタイムアウト してしまうような事もあった。実際、深夜の障害対応中に「hot fixでバージョン戻してReleaseしましょう」「では、lockします」「・・・(終わりは3時だな)」といった会話が発生するなど、本当にあった怖い話もいくつか体験しており、流石にlockファイル生成速度の問題を看過できなくなっていた。
先述した通り、pipenvの設計思想の課題の1つである、has値確認のためのbuild実装に起因するもので、根本的な解決が難しいことも考慮し、別ツールへの移行を考える必要があった。検討したのは、pip-tools、poetry、flitであった。中でもpip-toolsは強く検討したが、各々がenvを設定するコストやpyproject.tomlが今後主流になるだろうという憶測から、poetryとflitに絞って検証を行った。
移行当初、flitが抱えていた課題として、パッケージのバージョニング機能が不十分であるという課題が存在した。具体的には、gitタグやVERSION.txtを通してパッケージのバージョンを決める方法の有無で、これによってCIによるバージョンやpublishを行う所作が、所属チーム内では広く行われていた。
poetryには、poetry-dynamc-versioningという拡張が存在し、こちらを利用する事で、上記問題が解決できる事が分かったため、以降先としてpoetryを利用していく運びとなった。github.com
乱立するファイルと管理場所
所属チームでは、基本1人1プロジェクトで開発を進めており、そのプロジェクト数は大小や稼働率 、廃止撤退様々あれど36個にも登る*26 。
私が入社当初、プロジェクトテンプレート等はなく、各々自らが知るツールを使ってRepositoryを作っていた。その後、私がcookiecutterによるプロジェクトテンプレートを作ったものの、そういうった背景を鑑みないrepoは増え、プロジェクト管理は以下のようなファイルに分散していた。
requirements.txt
setup.cfg
setup.py
VERSION.txt
Pipfile
Pipfile.lock
pip.conf
code_analysis.conf
yapf.ini
MANIFEST.in
中にはバージョン情報がrequirements.txtとPipfileに分かれて書かれており、初見ではどこで指定されているモジュールがproductionで使われているのか分からないようなプロジェクトも存在した。poetryとpoetry-dynamc-versioning、toxというテストを統一的に管理するツールを導入する事で、以下の3つに全てのファイルを集約できる事が大きな後押しになった。
pyproject.toml
poetry.lock
tox.ini
github.com
これは、最近Preferred Networks社のブログでも語られたような内容なので、普遍的に多くの企業で課題になっているだろう。tech.preferred.jp
私の所属企業では、poetry、poetry-dynamc-versioning、toxを利用する事によって既存のメンバーだけでなく、新しいメンバーに対しても混乱を産まず、いくつかの設定の場所と使い方を覚えるだけで開発に専念できるようになり、多くの問題を解消することができた。企業によっては、インフラやCI、要件の関係で他ツールを選ぶこともあるだろうとは感じるが、横串でツールの要件が決まっている事での開発速度の差は何より大きい。
gokartなどOSS との管理方法統一
私の所属企業として内部で使われるツールを外向けのOSS として公開しているが、チームメンバー全員が使うにも関わらずメンテナが一部のメンバーに偏ってしまっていた課題があった。様々な理由こそあったが、日頃使っているツールとの差異が大きく、パッケージングやフォーマッタのツールに社内との微妙な違いがあり、またbuildやpublishをメンバー個人ができない状況で、新規に開発に参入しづらいという課題が大きく存在した。
そういった背景から、社内でpoetryを推進した後、外部のOSS をpoetryに移行する運びで解消する事にした。github.com
活動全体の結果
先述のような前提を踏まえ、私が2020年4月にpoetry移行をスタート。
2020年4月に自己宣言 1年かけて、コツコツと様々なプロジェクトにPull requestを出し、先日稼働中のプロジェクト全てがpoetryに移行した形になった。
ROI勘定
移行時は、pyproject.tomlがデファクトスタンダード にならなかった場合にpyproject.tomlに多くの設定が集約される事でロックインされてしまうのではという懸念を持っていたが、現状多くのフォーマッタやlinter、testツールがpyproject.tomlをサポートする流れになっており、良い選択だったと言える。
poetry-dynamic-versioningを利用した、python パッケージ用のrepoの設定の仕方の記事を書くなどした。vaaaaaanquish.hatenablog.com
また、同僚の @SassaHero がyapfをpyproject.tomlの対応をするなどした。
チーム管理のOSS であるgokartには、poetryやtoxが導入、かなり少ないツールと設定ファイルで多くの処理が行えるようになった。結果社内外からのコミッターも増えて万歳という結果になった。
まとめ
pipenvからpoetryへの移行を行った。要点としては以下のようになる。
社のVPN 起因でpipenvのlock速度に課題があり技術的解決も困難であったため乗り換えを決意した
乗り換え先の選定においてはversioning等の既存のCI、OSS の移植の簡易さを考慮した
数十のプロジェクトで1年単位での移行となった
結果として課題が解決するだけでなくpyproject.tomlへの情報集約、OSS の盛り上がり等の副次的効果も得られた
poetry移行により、この先少なくとも5年は持つ開発環境が作れただろう。何よりlockやinstall速度が改善した事が成功の証と言える。
しかし、再三記述した通り、あくまでパッケージツールであって、かつ安定した状態とも言えないため、今後どうなるかは定かではない。移行作業も多くの時間がかかるし、新しいツールも続々出てくる。ベストプラク ティスといった言葉に惑わされず、より丁寧な技術選定の上で今の自分たちにあった選択が出来るようにすべき、ということがよく分かる。
- おわりに -
本記事では、pip、pipenv、poetryという3つのパッケージ管理ツールについて、技術的、歴史的背景をまとめ、それらを元にpoetry移行を行った経験を綴った。
そもそもパッケージ管理が最初から全て上手くいっているプログラミング言語 などない。フロントエンド系だって、様々な設定ファイルやメタプログラミング を通してpackage.json やtsconfig.json に行き着いているし、JVM 系のようにhash照合の概念がなくpackage registryをSpringが立てているようなところもある。package registryを捨て、gitのコードベースに依存解決を行っている言語もあれば、RustのCargoを見れば、fmtからtest、doctest、build、パッケージ依存解決、パッケージングを行えるたった1つのツールをメンテしている。それぞれ見れば、それぞれに課題がある。
各ツールを組み合わせ、自分の最強のbuild環境を作る上では、ある意味Python の体制は良く出来ていて、動的言語 との相性も良い。一方で、出てくる不満についてもよく分かる。
Python にもCargoくらい全ての事が詰まったツールは欲しい。
特にpyproject.tomlベースでPEP 582も扱いたいし、できればtestやlinterも1つのツールに収まっていて、
スクリプト で管理するのはごく一部でロックインされず気軽に乗り換えられるのが嬉しいが、そんなモンスターのようなツールのメンテは想像するだけで骨が折れる。
PyPI の
json -
api がPEPを通るか、Anacondaのようにpackage registoryを構える偉大な団体が出てくるかといった依存解決についての解消も必要だろう。
一方で、これは作ってない人のお気持ちであって、pyproject.tomlとbuild script以外にPython を書くツールも出てきており、pyproject.toml以外の選択肢がパッケージングという観点以外のlinterやapi config、その他設定を起因に出てきた時移行できるよう、ロックインを避けるようにしていくのがベターだろう。
Python がC/C++ のwrapperとして多くの機能を持っている事も加味すれば、今後もbuild scriptは必須になるだろうし、元来、パッケージ管理ツールといった代物はプロダクトコードとは別のレイヤーに居るのだから、あとはプロジェクトのサイズ感や運用状況と相談し、ベストプラク ティス等と言わず、そういったツールに固執 せず、粛々と運用し、適切に時期をみてツールを変更していくだけという話である。
アメンバー でもなければ、パッケージ管理ツールの主要なコミッターでもないので、大きく発言する資格はないし、donate.pypi.org やNumFORCUS を支援するか、issueやcommitやコメントを重ねるか、自分で理想のパッケージを作るかをやっていかないといけない。それがソフトウェアエンジニアとしての常である。頑張りましょう。
Twitter かはてブ に書いて頂ければ幸いです。
// -- 2021/03/29 追記 --
GitHub がpackage registoryに成り得るサービスを展開していて、Python もfuture workに入っている。ここにindexされ、常用が始まるのを機に後方互換 が一気に変わって、依存解決が超簡単になって、管理もGitHub ないしMSがやってくれるというコースもワンチャンあると思っている。その場合、ユーザが利用するツールがどう転ぶかは未知数だ。などとGitHub Packagesが出てから思い続けて、future workになって2年経つので、いつになるかはよくわからない。一応future workになった時点で2021年の3月以降とされているから、今後なにかある可能性は高い。















")
")

")










