- はじめに -
今回、技術書典11に「Rustによる機械学習概覧」というタイトルで、所属企業であるエムスリー株式会社の執筆チームより出る「エムスリーテックブック3」に文章を寄稿した。
執筆チームからの熱いコメントは以下。
販売ページは以下。
techbookfest.org
本ブログは、エムスリーテックブック3を企画して立ち上げてから、自分で同人誌を書くまでのお気持ちを綴った、所謂ポエムである。
- Rustによる機械学習への想い -
ポエムといえば自分語り、自分語りといえばポエム。まず思い出に浸ろう。
私が機械学習を初めて実装したのは高専の頃。あの時はC/C++とJava、C#なんかを使って、何とかアルゴリズムを理解して実験していた。VisualStudioの起動に悠久の時が必要だったので、朝研究室に寄ってPCとVisualStudioを起動するボタンだけ押して授業に行ったものだ。遺伝的アルゴリズムでゲーム攻略したり、音楽作ったり、ニューラルネットでどうでも良いネットの動画の再生数とかを回帰で解いて遊んでいた。大学に入って、MatlabやLispを触ったが、何より初めて触って衝撃的だったのはPythonだったと思う。当時は、OpenCVが驚異的に簡単に扱えてNumpyで演算が出来て、OpenMPやCUDAといった資産も扱えるすごいFFIを備えたやつという感動があった。当時のDeep Learningのライブラリといば、cudaないしドライバのinstall battleに始まり、激しいPythonのインターフェースとバージョン差異との戦いの連続だった。そして、prototxtオジサンと呼ばれる(私が勝手に呼んでいる)「昔はprototxtでネットワークを定義してたんだよ…」と若者に言って回る人を大量に生み出していった。私もだ。この時は想像もしなかったが、後に出るChainerは偉大なのである。その前後、何故か縁があり、アルバイトもはじめてPythonでCNNやらを実装してワイワイしていた。いつの間にかPythonを沢山書いて、研究でも利用するまでに至っていた。Pythonだけとは言わず、一時期Juliaを使って更に良いとなってコンペに出て入賞したり、Julia Tokyoにも登壇した。就職して最初の会社はC#の会社だった。画像認識をやっている部署だったが、OpenCVSharpの開発者が居たのが大きい。C#は好きな言語の1つ。その会社にPythonのAPIを初めて導入する役割もやった。ライブラリなど様々な事情でPython2で実装したのを今でもたまに悔やみ心の中で謝っている。一度転職を経てからはPythonがメインになった。転職先は大きい企業だったので、Rが得意なおかしな人が沢山居てRの講義なんかも受けた。R悪くない。この頃にはもうPythonにおけるDeep Learningのフレームワークというやつは概ね今の基盤が出来上がっていたように思う。破壊的変更で死んだり、supportが終わったり色々あったものの、分散化やタスクの複雑化、モデルの巨大化を見れたのは楽しかった。次の転職先、つまり現職では本当にPythonだけになった。速度の遅いPythonが機械学習というタスクで好まれる訳がないと言っていた私もあの人達も、みんなwrapper言語としてのPythonを業務で書くただの人になっていった。
はてさて、雑に今までのプログラミング言語と機械学習の思い出を振り返ってみた。
私と同世代くらいの人は頷く場面もあるかもしれない。
私自身、ここまで、様々なプログラミング言語を使って、機械学習アルゴリズムを書いたり使ったりしてきた訳だが、現状それらは概ねPythonとRに収束しつつある。例外を除けば、一部C/C++を書く場合があるといったイメージだと認識している。
そんな中で、私は1年ほど前にRustと出会った。Rustは、非常に良いプログラミング言語であり、私は機械学習分野にもパラダイムシフトを与えてくれると思っている。
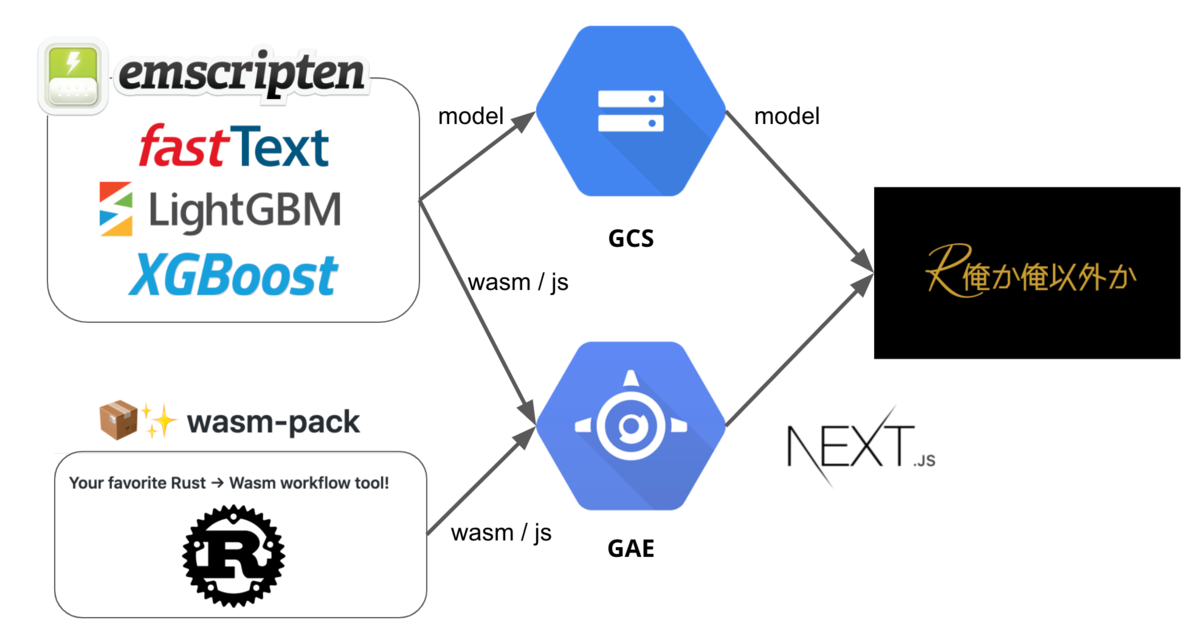
お気持ちだけじゃなく、実際Rustで形態素解析から機械学習モデルを使った分類タスクを解くExampleになるようなブログを趣味で書いたりしている。
vaaaaaanquish.hatenablog.com
それをwasmにして実際にWebサービスにしたりして遊んでいる。
vaaaaaanquish.hatenablog.com
このサービスはなんやかんや2万強のアクセスがあるので、Rust × MLなWebサービスでも結構多いユーザだったのではと思うが、いかんせん他の事例が無さ過ぎて分からないままである。
他にもRustによる機械学習実装、ブログ、動画、本、事例、実装例をまとめたRepositoryを作ったりしている。あんまり更新してないけどStarして欲しい。
github.com
LightGBMのRust bindingsも作っている。最近LightGBM本家のREADMEに載って、Microsoftの人からGreat的なメールを貰って嬉しかった。褒めて欲しい。
github.com
大体これくらいやっていると「Rustで機械学習する価値って何?」「Rustは何が良いの?」「PythonやRはなくなるの?」という声が必ず聞こえてくる。
なんと、それに答える気持ちを全部乗せて書いたのがこのエムスリーテックブック3だ。是非読んで欲しい。
techbookfest.org
中身から少しだけ抜粋するが、Rustユーザ、機械学習ユーザの意見は概ねどのディスカッションや事例でも一致している。機械学習をやる上でのRustの良さは速度と既存の資産との相性、wasmの存在になる。どのディスカッションもC/C++で書かれた一部が置き換わる、wasm利用例が増える、エッジデバイスや高速化などが必要なピンポイントでの利用が増える、という所に落ち着いていて、PythonやRのエコシステムは残るし、むしろそれらと協業してやっていく良い形が探られるだろうというものになっている。
かつて色々な言語を乗り越えて、Pythonという言語が今機械学習やデータサイエンス業界で使われている。今度は、乗り越える対象ではなく、その屋台骨の一つとしてRustがくるぞという話なのだから、これはエムスリーテックブック3を買って未来に想いを馳せる他無いだろう。
- エムスリーテックブック3の立ち上げ -
今回、技術書典に出すにあたって私が「やりましょう!」と言い出して、社内説明会を開いて、人を集めて、Re:VIEWやCIを整備して、レビューして、最後TeXでフォーマットを直して出稿するところまでを主導した。
エムスリーとして技術書典に出るのは私自身は2回目で、前回エムスリーテックブック2でも執筆した。
エムスリーテックブック#2:エムスリーエンジニアリンググループ執筆部
この時は、同僚の@mikesoraeが主導していたが、コロナ禍でオンラインになり勢いが弱まっていたので、手を挙げた。
大して書きたい気持ちが強かった訳でもネタがあったわけでもないが、技術書典のような業界内でも著名なイベントに少しでも多くの若く優秀な同僚を出して市場価値を上げて欲しい気持ちがあった。本を書くのは大変なので、経験しておくだけでも良いし、ブログより長い文章で公開できる技術書にするまでの工程は、自身の知識の整理と技術説明力の向上に役に立つ。会社の広報が難しいオンラインの時期だからこそ、PDF以外に「後から配送」による物理本を送れる技術書典は、良い広報にもなると何となく思っていた。



そういう想いや過去の売上から会場、打ち上げの様子、大変な部分をスライドにまとめて、社内説明会を開いた。テックブログの平均文字数と比較して「ね?簡単でしょ!」と言おうと思ったけど、同人誌とはいえ普通にちゃんとした本を書くのは大変だという事もわかった。
こんな感じで調子良くやってたが、書くのはめっちゃ大変で結果出来上がったのは7月入ってからだった。申し訳ねえ。
でも実際エムスリーテックブック3は、私が読み返しても結構面白い多様な分野と専門性のある仕上がりになっているし、後は皆さんに買ってもらうだけだ。少しでもエムスリーテックブック3の良さが伝わればと想い、今こうしてポエムまで書いている訳なので、是非とも手に取って頂きたい。
今は、社内向けのRe:VIEWテンプレートを作って、Confluenceに技術書典に出るまでの手順書、過去の経歴のまとめを作っている。いずれ、私が居なくなったとしてもこの文化が続いて欲しいと強く思うし、この書籍でエムスリーを知る人、またこの書籍でエムスリーの優秀な若手のエンジニアが採用したくなっちゃう人が続々出てきて欲しい。
- おわりに -
久々にポエムを書いた。
ちなみに他の寄稿者良いです…
技術書典11エムスリーテックブック3のオススメの章は私の駄文ではなく同僚が書いたハイパーカジュアルゲームのビジネスロジック解説と入門が説明されてる章です…
— ばんくし🎃 (@vaaaaanquish) 2021年7月6日
買ってね。
techbookfest.org
P.S.
Practical Machine Learning with Rust: Creating Intelligent Applications in Rust https://t.co/o8p4IexE1y
— ばんくし🎃 (@vaaaaanquish) 2021年7月4日
Rust ML本読んで一通りコード動かした。教師あり/なし、NLP、CV、レコメ、スクレイピングやMLのための良いコードの書き方、PythonやJavaとの連携まで抑えた網羅的な書籍で良かった。
さて、『Practical Machine Learning with Rust』を最後まで読んでやってみてこれで良くねってなった技術書典に向けて書いてたRust ML本を頑張る気持ちがゼロになったわけだが…
— ばんくし🎃 (@vaaaaanquish) 2021年7月4日
自分が書こうと思った時、既に良い本が世の中にはあるものだ。