- はじめに -
最近、PythonのパッケージインストーラーであるpipをRustで書き直したripというツールが公開された。
ripのREADME.mdには、flaskを題材に依存解決とインストールが1秒で終わるようなgifが貼られている。
この速さは一体どこから来ているのか調べた。
- 宣伝 -
来週開催の技術書典15で「エムスリーテックブック5」が出ます。
私の内容は「自作Python Package Manager入門」で、CLIツールの作り方から始まって40ページでPyPIの仕様やその背景となっている要素を把握しながら、lock、install、run、build、uploadといったサブコマンドを実装してPackage Manager開発者になろうという内容です。Python開発経験2年くらいあれば作れると思います。
本誌ではまさかの「いろんな言語のパッケージマネージャ比べてみた」というパッケージマネージャネタ被りが起きており、こちらでは同僚がCargoやnpm、poetry、go mod、pnpm、yarnといったツールの内部実装を比較しています。本記事と同様にPackage Manager完全理解者の道を歩む事ができる本になっています。
# オンライン開催
- 会期:2023/11/11 (土) 〜2023/11/26(日)
- 会場:技術書典オンラインマーケット
# オフライン開催
- 会期:2023/11/12 (日) 11:00~17:00
- 会場:池袋・サンシャインシティ 展示ホールD(文化会館ビル2F)
12日は家庭の事情で午後からにはなりますが多分会場に居ますのでよろしくお願いします
- ripの成り立ち -
ripは、prefix-devというOrganization配下にある。
このprefixという会社は、実はAnacondaやその周辺ツールと関係があるため、まずその成り立ちから書いておく。
Anaconda
Anacondaは、知っての通りAnacondaリポジトリや周辺のcondaエコシステムに影響を及ぼす偉大な企業である。
あまり特別な情報はないが、会社のHistoryを見ていて2012年に出来た企業だと知って「思ったより若い」って思った。
もっとこうずっとあるイメージだった。
mamba-org
2022年、condaのエコシステムに大きな影響を与えた、「Mambaプロジェクト」というものがある。
フランスにjupyterやConda-forgeの開発者が集まるQuantStackという会社があり、そこに所属していた開発者@wuoulfが主軸になったOSSプロジェクトである。QuantStackの他の開発者も多くMambaプロジェクトに参画している。
BloombergやNumFOCUSなどから出資を受けているプロジェクトでもある。
Anacondaリポジトリやconda-forgeなどのcondaエコシステムへのアクセスは、CLIツール「conda」が長く利用されてきた。condaは大部分がPythonで書かれたツールであるのに対し、Mambaプロジェクトではcondaの互換性を保った形で多くをC++で再実装したツール「mamba」を開発、提供している。mambaはcondaに比べ、依存解決やパッケージのbuild方法の変更、並列化を行う事でも高速化されており、CLIツールとして表面だけ見てもより手軽にcondaエコシステムにアクセスできるようになっている。
そもそもMambaプロジェクトは、先に挙げたような便利な代替CLIツールの再実装やそれらの高速化とは別に、以下のような問題を解決するために立ち上がったプロジェクトであり、CLIツールはその結果の1つにあたる*1。
- condaはOSSだが、Anaconda Incが作るAnacondaリポジトリの実装は非公開である
- conda-forgeエコシステムも良い感じだが、コミュニティで管理されてる分アーカイブもないし安定性には欠ける
- condaはサードパーティのconda-forgeの巨大なリポジトリを見に行く時にメモリ効率が悪い実装になっている
故にMambaプロジェクトでは、CLIツールのconda代替「mamba」以外に、conda packageホスティングサーバの「Quetz」mamba内で高速にPackage buildするためのconda-build代替「boa」などをそれぞれ並行して開発している。
非常に大きいプロジェクトである。
中でもCLIツールmambaの実装が、condaエコシステムユーザにとって大きな恩恵をもたらしているという話である。
内部で利用される依存解決アルゴリズム等を含むコア実装「libmamba」も、QuantStackらにより開発された後、NumPy、SciPy、Jupyter、Matplotlib、scikit-learnなどPythonやAI/ML関連のライブラリのコア開発者らが所属するコンサルティング企業Quansightによって、condaに移植される事になる。これにより、condaはv23.10.0から大幅に高速化した。
www.anaconda.com
prefix.dev
先述のconda-forgeのコア開発者でもありmambaの発案者でもある@wuoulfは、QuantStackでのmambaプロジェクト後に「prefix.dev」という会社をドイツで立ち上げる。パッケージマネージャー開発を主軸とする会社であり、毎年開催されるパッケージマネージャーの国際カンファレンス「PackageCon」の主催企業でもある。
prefix.devは、conda packageの思想を拡張した、cross-platformでmulti-languageに対応した高速かつ軽量なpackage managerである「pixi」を推して開発している。
世間一般ではcondaに関する言及の殆どがPythonやRに関するものであるため「condaエコシステムはPythonのためのもの」のような誤解があるが、conda packageの仕組みはaptやrpm等と変わらない。そのため、実際はどんな言語、どんなツールでもパッケージとして配布出来るし、installの仕組みを作る事ができる。prefix.devでは、conda package形式の高速なインデックスのホスティングやhuggingface.coのような実行環境まで開発しており、本気で様々な言語のPackage Managementをpixiで飲み込んでやろうと企む気持ちが伺える。これらのバックエンドは、先に示したMambaプロジェクトで開発されたツールや関連の技術が使われている。
prefix.dev
当然、prefix.devはmambaやlibmamba、conda関連のツールの開発も牽引し続けている。
その他にも、prefix.devはパッケージマネージャーに関わるツールをRustで開発している。
著名な依存解決アルゴリズムbacktrackingのRust実装「resolvelib-rs」、libsolv(CDCL)のRust実装「resolvo」、condaエコシステムとのAPIのやり取りをRustでwrapした「Rattler」、そして今回の本題の1つ「rip」など、精力的に新しいツールを開発している。
mambaが全体的にC++で書かれており、そこから得られた知見を活かして、多くをRustで書き直そう、というスタイルのようだ。イカしてる。本当に頑張って欲しい。
- condaがinstallで行うこと -
話はロジック面に入る。先に示した通り、conda packageはPython以外でも扱えるようなフォーマットであり、condaエコシステムないしconda packageの構造は、PythonやPyPIのものとはかなり違う*2。中身はさておき、Package Managerが気にするべきは、そのメタデータ取得方法になる。
Pythonパッケージの場合は多くの場合METADATAファイルを読みパッケージ情報を取得するが、conda packageの場合はrepodata.json(またはcurrent_repodata.json)である。repodata.jsonを含むファイルの構成は以下のようになっている。
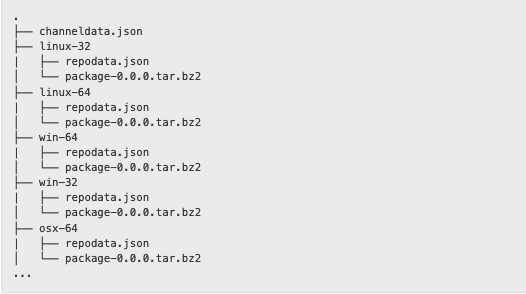
この構成のリポジトリに対して、condaが行うinstall作業は以下のようになる。
- 関連するrepodata.jsonファイルを全てダウンロードしてメモリ上に乗せる*3
- すべての依存関係の中から環境で使用される可能性のあるパッケージを絞り込む
- 例: cudaが必要な場合はそうでない物を削る
- SATとしてSATソルバを再帰的に実行する
- SATソルバを呼び出す前に優先度決定、pruningを毎回実行する
- 例: 満たす必要のなくなった依存関係を先んじて削ってしまう
- 例: 可能な限り最新バージョンを使う
- 例: pruningとして削除された関連ファイルが多いパッケージを優先する
- パッケージ内の優先度をパッケージ開発者が決めれたり*4もする
- SATソルバを呼び出す前に優先度決定、pruningを毎回実行する
- SATソルバの結果得られたパッケージをinstallする
- install_scriptを走らせる
- 必要に応じてhard link/soft linkが使い分けられる
SATソルバは、元々PicoSATだったものが、CryptoMiniSatになり、現在はlibmamba(libsolv, CDCLの拡張実装)となっている。
この場合、速度において重要なのは、SATソルバとCaching戦略と依存解決を行う優先度の3つになる。この辺りはcondaの長い歴史の中で磨かれてきたものがあり、優先度ロジックは以下の「Running the Solver」にまとまっている。1つ1つはあまり難しいものではないので以下記事を参照して欲しい。
www.anaconda.com
mambaは、condaの積み重ねてきたテクニックを踏まえつつ、大きく再実装を実施することで速度面を改善している。
- mambaでの速度改善 -
mambaの大掛かりなC++採用において、依存解決ロジック周辺の変更は速度に大きく影響している。
condaは、PicoSATのPython wrapperであるpycosat、CryptoMiniSat(msoos/cryptominisat)のPython wrapperであるpycryptosatを依存解決に利用していた。先のcondaのinstallのロジックの説明の通り、condaの実装はSATソルバと他ロジックを複数回行き来しており、依存解決はC++、優先度決定やCachingの戦略はPythonという形になっている。Pythonとのやり取りがボトルネックになるため、mambaではrepodata.jsonを取得後、前章②の段階からC++に情報を渡す実装となっている。これにより「複数回のSATソルバ呼び出し」が無くなった。また、C++を直接扱えた事で、libsolv、libarchive、libcurlなどの強力なC++資産をそのまま扱う実装にもなっている。「優先度決定等のためのPythonとC++間のオブジェクトの行き来」も大幅に無くなり、これらが速度に影響を与えている*5。
依存解決のロジックは、openSUSEなどで利用、開発されている信頼と実績のあるlibsolvを叩く形に変わった。
アルゴリズムは変わったが、その際のベンチマーク自体には大きな変化は現れていないようなので、上記のC++再実装によるリファクタ効果が大きかったように感じられる。
全体感としては、開発者の@wuoulfによる記事やPackageConの動画があるため、そちらを参照するとよい。
wolfv.medium.com
www.youtube.com
また、repodata.json.zstといったストリーム可能な圧縮形式を用いてパッケージ情報取得を高速化している。ファイルのダウンロードにおいても、dnfなどでも使われるlibrepoをガッツリC++で書き直した「powerloader」も開発している。これにより、ファイル取得の並列化やrestart可能な分割ダウンロード、zchunkなどをサポートしている。powerloaderを利用して、repodata.jsonが更新されても更新されたbitのみ取得する方法も実装されており、ファイルダウンロードの側面からも速度が改善されている*6。
- ripに応用されたこと -
ここまでで得られたテクニックを利用し、Rustでまるっと書き直したのがripにあたる。
Rustで書くことで、asyncで高速に依存解決とinstallができるようにな実装になっている。依存解決はlibsolv(CDCL)のRust実装「resolvo」をprefix.devが自前で作り利用している。これによって、PythonやC++な部分が無くなり*7簡素で高速な実装になっている。前述したpixiにもresolvoが使われており、issue上ではpubgrub-rs作者との交流もあり、PubGrub*8導入などさらなる進化の余地を考えられているといった所だろう。
ロジック面のポイントとして、resolvoに入っているIncremental solving*9という考え方が高速化に繋がっている*10*11。
Pythonパッケージにおいては正確なメタデータがPyPI APIから返ってこないため、METADATAファイルに何らかの形でアクセスする必要がある。これがいかんせん高コストである。なので優先度付きキューにメタデータ取得処理を詰め込んで、Solverは非同期的にPackageの情報を取得、追加しながら探索を行う。故にIncremental。また、その際の探索パッケージの優先度決定はPubGrubのdecision makingに似た考え方を採用しており、最新バージョンを優先しながらもなるべく依存パッケージが少なくなる方向性に向かう*12。この実装により、Solverがメタデータ取得等で殆ど止まる事なく依存解決を行う事が出来ている。またファイルの分割ダウンロード等も実装されており、resolvelib-rsやpowerloader等を作成した経験、pubgrub-rsへの貢献を経て作成された依存解決ライブラリである事が伺える。
注意点として、Pythonパッケージのフォーマットはsdist/bdistの2種類があるが、ripはsdistに対応していない。
condaエコシステムと違い、PyPIの依存解決が高コストな理由うちの1つにsdistフォーマットがある。近年ではbdist(wheel)が十分広まりつつあるので、比較的新しいバージョンを指定すれば正常かつ高速に動作するかもしれない。一方でsdist未対応につき、installできないパッケージやバージョンが存在するという欠点にも繋がっている。また、ベンチマークでsdistが依存関係に入るものと比較する場合、それを実際使わずともsdist対応パッケージマネージャーは勝てない要素が多くなるので、公正なベンチマークが求められる。この辺りが今後asyncと絡んだ時にどうなるかポイントで、実際ripがsdistに対応した時の速度がどのようになるか未知数だと思われる。
- おわりに -
今回、mambaやripについて調べた。
元々conda周り知ってないとなと思って調べてあったが、エムスリー エンジニアリングフェローの@SassaHeroが気になっていたので「技術書典の熱も余ってるし書くか〜」と思い書いておいた。
名前がアレだけど、なんで速いのかは気になるなhttps://t.co/x3H7RXQ8GI
— Tohirohi SASSA (@SassaHero) 2023年10月22日
コードは読んでいるが、condaをユーザとして使い倒しているわけではないので、もし間違いがあればこのブログのリンクと一緒に参考リンクをXで呟いておいて欲しい。
Rustのパッケージマネージャーといえば一時期ryeが話題になったりもしたが、ryeはRustとはいえ中身は殆ど既存のPython資産を叩いているもので、実際既存ツールと同じ問題に行き着いている様子が伺えていた。もっとRust寄りのパッケージマネージャーだとhuakがあるが、ずっとWIP状態である*13。しかしながらripの精力的な開発を見ていると、JSやCLIツール群がそうであるように、PythonのPackage Manager周辺にもRustが増えそうな感じがしてくる。依存解決などの難しい部分をprefix.devがRust化しているというのが明らかに大きい。Linterには最近よく使われる所でRuffがあるし、env環境マネージャーもyenのように挑戦者が居る。必要最低限のツールが出揃いつつある中で、シレッとprefix.devがこのまま全てRustなPython Package Managerを出してしまう気もする。
今後もPyPA等が公に導入することはなかなか無いだろうけど、こういったconda系統を経由してサードパーティとしてRustが増えていく感じがあるのは、Pythonの多様なユースケースの結果と捉えると面白い。
なお、こういったPyPI周辺のお話を日本語で知りたい場合は「PyPI APIとメタデータ取得はどうなっているのか」「sdist/bdistとはどういう歴史で生まれた何なのか」「どうPythonパッケージをインストールするのが正解か」「これからこの問題はどのようになっていくのか」を技術書典の本の方に書いたので参照されたい。
是非どうぞ
*2:conda installのドキュメントもしくはconda開発者の2015年スライドが全体感を掴むのに良い
*5:実装は読んだが私が実際にベンチマークした訳ではないので実態は不明
*6:libmamba vs classic — conda-libmamba-solverが詳しい
*7:正確にはPythonのパッケージ情報を扱うpackagingだけvendoringされているが
*8:PythonのPackage Managerを深く知るためのリンク集を参照して欲しい
*10:公式のブログが後日出るらしい https://prefix.dev/blog/introducing_rip#step-2-make-the-solver-lazy
*11:こちらも詳しい https://github.com/pypa/pip/issues/7406#issuecomment-583989243 https://github.com/pubgrub-rs/pubgrub/issues/138
*12:solver/decision*.rs

")
![実践Rust入門[言語仕様から開発手法まで]](https://m.media-amazon.com/images/I/51e5B1Zx+yL._SL500_.jpg "実践Rust入門[言語仕様から開発手法まで]")



